AWSから提供されているAIツールの一つ「Amazon Comprehend」がいつの間にか日本語に対応していたので試しに利用してみることにしました。

Comprehendは文章を解析し、単語が人なのか場所なのか意味付けを行ったり、今回チャレンジするどういった感情の文章なのか判定すると言ったことが可能です。予想外にComprehend先生はBL好きではないかという疑惑が生まれましたw 詳しくは本文でどうぞw
最終的なコード
最終的なコードをGitHub上にアップしています。結論が見たい方はこちらをどうぞ。 github.com
Comprehendの感情分析を試してみる
Comprehendに文字列を送信すると以下の4つの指標が返ってきます。この中で一番信頼性が高かった物が文字列の感情と考えることができます。
- ポジティブ(POSITIVE)
- ネガティブ(NEGATIVE)
- 中立(NEUTRAL)
- 上記が混ざっている(MIXED)
青空文庫編
青空文庫の小説を1行ずつ感情分析にかけてみました。
「走れメロス」太宰治
波乱万丈なストーリーなので期待していたのですが思った以上にNEUTRALだらけになりました。
そしてポジティブに捉えられるのが66行目の「「ありがとう、友よ。」二人同時に言い、ひしと抱き合い」や、72行目の「「メロス、君は、まっぱだかじゃないか」になるあたりComprehendさんBL好きなのか…と疑っちゃいますねw 🤔
「ごん狐」新美 南吉
国語の教科書で皆が涙したおなじみのお話ですが、こちらは期待通りネガティブだらけの結果になりました。
Comprehendには1行ずつ送っている関係で連続した文章ではなく、各行はすべて独立したものとして分析されるので人間が読んだときは違った印象になりますね。長文の場合はどこまでを分析対象として一括で投げるか考える必要がありそうです。
- 青空文庫:ごん狐より
「銀河鉄道の夜」宮沢賢治
こちらもネガティブが多くなりました。もともと明るいお話ではないのもですが宮沢賢治先生の文体にも影響されているのかもしれません。
その他のパターンを試す
小説だと思ったように行かなかったので他のパターンもいくつか試してみます。
自分のツイートを12件ほど適当にかけてみました。皮肉とか冗談の判定はちょっと苦手なのかもしれないですね。あと「ヤバい」みたいな複数の意味に取れる言葉も難しいようです。
その反面、ポンポさん(映画)は一部ダメ出ししつも基本的に絶賛というわかりやすい文章だったのか予想通りの結果になりました。素直な文章の方が結果が出やすいですね。
ちなみに「映画大好きポンポさん」おすすめです!ぜひ劇場でご覧ください(・∀・)作画が良いというのもあるんですが、モノ作りが好きな人はぐっとくるシーンであふれてますよ。逆に創作活動に興味がない人は退屈かも。 https://www.youtube.com/watch?v=WN-j_AcMB3I
絵文字
絵文字の表情を何パターンか試してみましたが、いずれも中立となりました。絵文字だけでは感情は測れないみたいですね。
料金
1文字からの従量制となっており使えば使うほど単価が安くなりますね。なおAWSの料金はちょいちょい変わりますので気になる方は最新の情報をご確認ください。
| 文字数 | 料金 |
|---|---|
| 10Mユニット | 0.0001 USD |
| 10M〜50Mユニット | 0.00005 USD |
| 50Mユニットを超える | 0.000025 USD |
注意すべきは「ユニット」という単位が利用されている点です。
- 100文字で1ユニット
- 1リクエストに付き最小3ユニット(300文字)分を消費する
例えば150文字と250文字の文章をそれぞれ1回解析した場合の料金はどちらも同じになります。ギリギリ299文字まで詰め込んだ方がコスパが良いということですw
準備
IAM
AWSのマネジメントコンソールなどでComprehendが利用できるポリシーをIAMに付与します。
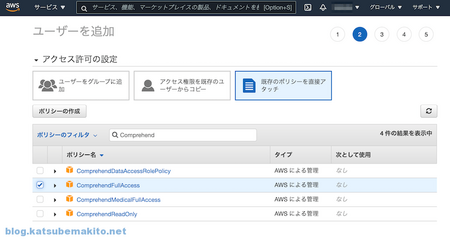
作成したIAMのアクセスキーIDとシークレット、利用するリージョンの指定を「.env」というファイル名で保存しておきます。このファイルはGitなどのリポジトリには絶対に登録しないでください。
AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXX AWS_SECRET_ACCESS_KEY=YYYYYYYYYYYYYYYYYYYYYYYYYYYY AWS_REGION=ap-northeast-1
Node.jsのプロジェクトを作成
Node.jsをインストール後、適当なディレクトリを作成し、package.jsonを生成するためにnpm initを実行します。
$ mkdir detectSentiment; cd detectSentiment $ npm init
必要なモジュールを入れます。
$ npm install aws-sdk dotenv
実際に解析してみる
ソースコード
AWSにSDK経由で解析したいテキストを投げつけるとJSONが返ってくるシンプルな作りです。
const AWS = require('aws-sdk') // .envの内容を環境変数化 require('dotenv').config() // IAM設定 AWS.config.update({ accessKeyId: process.env.AWS_ACCESS_KEY_ID, secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY, region: process.env.AWS_REGION }) // Comprehendに渡す値を準備 const comprehend = new AWS.Comprehend({apiVersion: '2017-11-27'}); const params = { LanguageCode: 'ja', // 言語 Text: 'お腹が減って死にそうです(^q^)' // 解析したい文字列 } // Comprehendで解析 comprehend.detectSentiment(params, (err, data) => { // エラー時 if ( err ) { console.error(err, err.stack) } // 正常なレスポンス else { console.log(data) } })
解析する文字列の制限
どのような文章でも解析できますが、次の制約があります。
対応言語
LanguageCodeには以下のいずれかの言語コードを指定します。このあたりはAWSの対応状況で今後増減する可能性もありますね。
| 言語コード | 言語名 |
|---|---|
| "en" | 英語 |
| "es" | スペイン語 |
| "fr" | フランス語 |
| "de" | ドイツ語 |
| "it" | イタリア語 |
| "pt" | ポルトガル語 |
| "ar" | アラビア語 |
| "hi" | ヒンディー語 |
| "ja" | 日本語 |
| "ko" | 韓国語 |
| "zh" | 中国語(簡体字) |
| "zh-TW" | 中国語(繁体字) |
レスポンス
先ほどのコードを実行すると以下のJSONが返されます。
{ Sentiment: 'NEGATIVE', SentimentScore: { Positive: 0.008115329779684544, Negative: 0.7191155552864075, Neutral: 0.27263563871383667, Mixed: 0.00013348308857530355 } }
分析結果としてSentimentScoreに前向き(Positive), 後ろ向き(Negative), 中立(Neutral) またはそれらの感情が複数混ざっている(Mixed)それぞれの信頼度が0〜1の間の数値で返ってきます。1に近ければ近いほど信頼度が高いことになります。
4つの指標のうち最も信頼度が高い指標がSentimentに入っています。