Node.jsの代表的なO/RMであるSequelizeの第二弾。
前回はインストールから基本的な利用方法までを取り上げました。今回はSELECT文にまつわるトピックスを取り上げていきます。

Sequelizeに限った話ではないですが、WHERE句の条件が複雑になってくると「これSQL書いた方が早くね?」という気持ちになりますねw
インストール
事前準備や基本的な利用方法については第1回を参照ください。 blog.katsubemakito.net
SELECT句
すべてのカラムを対象にする
何も引数に指定しない場合、すべてのカラムが抽出の対象となります。
const rows = await User.findAll()
この場合でもSQLでは*ではなくすべてのカラムが指定されるようです。
SELECT `id`, `name`, `age` FROM `Users` AS `User`;
カラムを指定する
特定のカラムだけを対象としたい場合はattributesで指定できます。
const rows = await User.findAll({ attributes: ['id', 'name'] })
SQLは先ほどとあまり変わりませんね。
SELECT `id`, `name` FROM `Users` AS `User`;
逆に特定のカラムだけを除外したい場合はattributesの下にexcludeで指定することもできます。以下ではタイムスタンプ関係を除外しています。
const rows = await Maker.findAll({ attributes: { exclude: ['createdAt', 'updatedAt'] } })
別名を付ける
先ほどのattributesには別名を付ける機能もあります。配列の2番目の要素に新しい名前をセットします。
const rows = await User.findAll({ attributes: [ 'id', // これはそのまま ['name', 'simei'] // name as 'simei' ] })
SELECT `id`, `name` AS `simei` FROM `Users` AS `User`;
なおasで別名を付けた場合はget()メソッドなどを通さないと取得できないようです。
rows.forEach(row => { const id = row.id const simei = row.get('simei') console.log(`${id}: ${simei}`) })
関数を実行する
レコード数を数えるCOUNTやMAX, MINなどを実行したい場合もattributesを使います。最終的に1レコードしか返ってこないのでfindOne()を使っています。
const rows = await User.findOne({ attributes: [ // count(id) as 'countRow' [sequelize.fn('COUNT', sequelize.col('id')), 'countRow'], ] });
実行されるSQLは以下の通り。
SELECT COUNT(`id`) AS `countRow` FROM `Users` AS `User` LIMIT 1;
COUNTにはcountRowという別名を使っていますので、getメソッドを使って取り出します。
console.log( rows.get('countRow') )
sequelize.fn()の'COUNT'部分をMAXやMINにすれば期待通りに動作します。GROUP BYと併用する方法については後述します。
FROM句
テーブルの関連付け
2つの1:n関係にあるテーブルの関連付けを行ってみます。
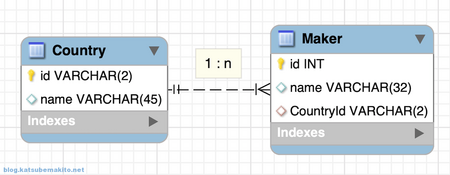
最終的に実行されるSQLは以下です。
SELECT `Maker`.`id`, `Maker`.`name`, `Maker`.`CountryId`, `Country`.`id` AS `Country.id`, `Country`.`name` AS `Country.name` FROM `Makers` AS `Maker` LEFT OUTER JOIN `Countries` AS `Country` ON `Maker`.`CountryId` = `Country`.`id`;
コードは以下の通り。クエリをすっきりさせるためにタイムスタンプ機能はOFFにしています。
// Modelを作成 const Country = sequelize.define('Country', { id: { type:DataTypes.STRING(2), primaryKey:true }, name: { type:DataTypes.STRING(32) } }, {timestamps: false}) const Maker = sequelize.define('Maker', { name: { type:DataTypes.STRING(128) }, CountryId: { type:DataTypes.STRING(2) } }, {timestamps: false}) // 関連付け // Makerの方に外部キーを設定する Maker.belongsTo(Country) // SQLを発行 !(async()=>{ // 初期データを挿入 await Country.bulkCreate([ {id:'JP', name: '日本'}, {id:'DE', name: 'ドイツ'}, {id:'AT', name: 'オーストリア'} ]) await Maker.bulkCreate([ {name:'Honda', CountryId:'JP'}, {name:'Yamaha', CountryId:'JP'}, {name:'Suzuki', CountryId:'JP'}, {name:'Kawasaki', CountryId:'JP'}, {name:'BMW', CountryId:'DE'}, {name:'KTM', CountryId:'AT'}, ]) // SELECT const rows = await Maker.findAll({ include: [Country] }) rows.forEach(row => { console.log(`${row.id} ${row.name} ${row.Country.name}`) }) })
1:n
個人的に一番良く使うのがこのパターンですが、ポイントは次の2箇所です。Model.belongsTo()で関連付けの設定を行い、findAllする際にincludeで関係するモデルを渡します。
// 関連付け Maker.belongsTo(Country) // SELECT const rows = await Maker.findAll({ include: [Country] })
Model.belongsTo()で関連付けを行うことによりこの場合は以下の外部キー制約の設定を行ってくれます。デフォルトだとカラム名が固定された状態(Country.id = Maker.CountryId)で設定されるため、命名する際に意識する必要があります。
CREATE TABLE IF NOT EXISTS `Countries` ( `id` VARCHAR(2) , `name` VARCHAR(32) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; CREATE TABLE IF NOT EXISTS `Makers` ( `id` INTEGER NOT NULL auto_increment , `name` VARCHAR(128) NOT NULL, `CountryId` VARCHAR(2), PRIMARY KEY (`id`), FOREIGN KEY (`CountryId`) REFERENCES `Countries` (`id`) ON DELETE NO ACTION ON UPDATE CASCADE ) ENGINE=InnoDB;
外部キー制約をこの例で言うCountry側に付ける場合はModel.hasMany()を利用します。この場合はCountry.MakerId = Maker.idの関係性で設定されます。
Maker.hasMany(Country)
1:1
この例で言うMakerとCountryが常に1:1になる場合はModel.hasOne()またはModel.belongsTo()を利用します。
// Maker側に外部キー制約 Maker.belongsTo(Country) // Country側に外部キー制約 Maker.hasOne(Country)
n:n (工事中)
ToDo: 後日追加予定
WHERE句
完全一致
whereの下にカラム名と値の組み合わせを追加するだけです。
const rows = await Maker.findAll({ // WHERE country='DE' where: { country: 'DE' } }) rows.forEach(row => { console.log(`${row.id}: ${row.name} ${row.country}`) })
複数のカラムを指定した場合はAND条件になります。
const rows = await Maker.findAll({ // WHERE id=1 AND country='DE' where: { id: 1, country: 'DE' } })
比較演算子
ちょっと複雑な比較を行う場合はOpを利用します。はい、このあたりから雲行きが怪しくなってきましたねw
const { Op } = require('sequelize') const rows = await Maker.findAll({ where: { id: { [Op.gt]: 3 // id > 3 } } })
このOpには以下のような様々な演算子が用意されています。MongoDBとかシェルスクリプトが頭をよぎりますね。
| 意味 | Sequelize | SQL |
|---|---|---|
| 同一 | [Op.eq]: 5 | = 3 |
| 同一でない | [Op.ne]: 5 | != 5, <> 5 |
| 〜を超える | [Op.gt]: 5 | > 5 |
| 以上 | [Op.gte]: 5 | >= 5 |
| 未満 | [Op.lt]: 5 | < 5 |
| 以下 | [Op.lte]: 5 | <= 5 |
| A以上B以下 | [Op.between]: [5, 10] | BETWEEN 5 AND 10 |
| A以上B以下以外 | [Op.notBetween]: [5, 10] | NOT BETWEEN 5 AND 10 |
LIKE/正規表現
文字列のパターンマッチもOpに用意されています。
const rows = await Maker.findAll({ where: { name: { [Op.like]: 'K%' // name LIKE 'K%' } } })
お馴染みLIKEの他に正規表現もいけます。個人的にはあまり使わないのですが、最近のMySQLには正規表現が標準で搭載されているのでそのままregexpとして実行されます。
| 意味 | Sequelize | SQL |
|---|---|---|
| パターンにマッチする | [Op.like]: 'K%' | LIKE 'K%' |
| パターンにマッチしない | [Op.notLike]: 'K%' | NOT LIKE 'K%' |
| 正規表現にマッチする | [Op.regexp]: '^K' | REGEXP '^K' |
| 正規表現にマッチしない | [Op.notRegexp]: '^K' | NOT REGEXP '^K' |
論理演算子
ANDやORもOpで書いてやります。
AND
ANDの場合は次のようにも書けますが、
const rows = await Maker.findAll({ where: { [Op.and]: [ {name: 'Honda'}, {country: 'JP'} ] } })
前述の通り以下の方がシンプルに書けますね。
const rows = await Maker.findAll({ where: { name: 'Honda', country: 'JP' } })
OR
OR条件の場合はこちら。
const rows = await Maker.findAll({ where: { [Op.or]: [ {name: 'Honda'}, {country: 'JP'} ] } })
IN
1つのカラムに複数のORを一度に設定できる便利機能のINは、Opも用意されていますが
const rows = await Maker.findAll({ where: { id: { [Op.in]: [2, 4, 6] } } })
以下のように単純に配列を指定するだけでもOKです。
const rows = await Maker.findAll({ where: { id: [2, 4, 6] } })
GROUP BY句
DISTINCTのように同じ値をマージするGROUP BYの利用法は以下の通り。関数やORDER BYと併用する方法は後述します。
const rows = await Maker.findAll({ attributes: [ 'country' ], group: 'country' })
HAVING句 (工事中)
ToDo: 後日追加予定
ORDER BY句
レコードの並び順を指定するORDER BY句はご覧の通り。通常のSQLと同様にDESCが降順、ASCが昇順です。ORDER BYには複数のカラムを指定できることから二次元配列である点に注意してください。
const rows = await Maker.findAll({ order: [ ['id', 'DESC'] ] })
結果をランダムに並び替えることも可能です。
const rows = await Maker.findAll({ order: sequelize.random() })
LIMIT, OFFSET(工事中)
ToDo: 後日追加予定
応用例
カラム内のデータをカウントし降順にソートする
特定のカラムの数をカウントし降順にソートするコードを書いてみます。最終的に実行したいSQLは以下。
SELECT `country`, COUNT(`id`) AS `countRow` FROM `Makers` AS `Maker` GROUP BY `country` ORDER BY COUNT(`id`) DESC;
Sequelizeのコードは以下です。普通にSQL書いた方が手っ取り早い気がしてきますねw ポイントはorderで並び替えを行う際にorder: ['countRow', 'DESC']とかできそうな気がしますがSequelizeのメソッドを通してやる必要があります。
const rows = await Maker.findAll({ attributes: [ 'country', [sequelize.fn('COUNT', sequelize.col('id')), 'countRow'] ], group: ['country'], order: [ [sequelize.col('countRow'), 'DESC'] ] })